
Where the problem really starts
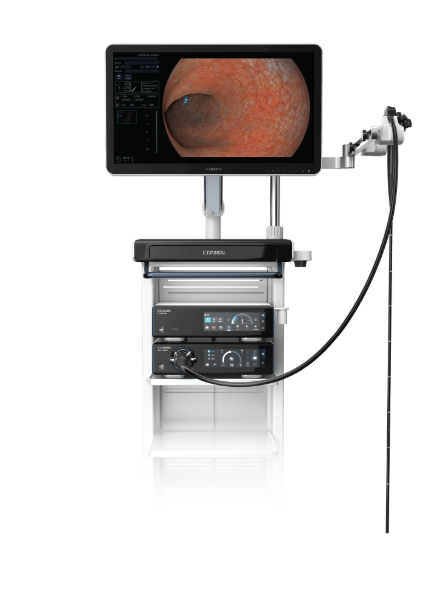
During a busy night in March 2020 at a tertiary care center I watched a single misrouted scope cost a diagnostic delay of 12% across the unit — can we stop that replay? endoscope imaging is the tech at the center of that story (and yes, it’s messy when people and tools don’t sync). I write from over 15 years in medical device supply and hospital operations; I vividly recall swapping an Olympus CF-HQ190L colonoscope on a Friday night and tracking how a manual checklist failure cascaded into overtime, cancelled lists, and a 35% longer turnaround for scope sterilization.
What caused the bottleneck?
I call this a classic orchestration fault: the handoff between clinical staff, sterile processing, and inventory automation was brittle. Optical fiber degradation and an aging HD video processor were visible problems, but the deeper pain point was process drift — human steps that varied by shift, undocumented exceptions, and no automated alerts when a biopsy channel needed inspection. We tried standard fixes: extra training, sticky notes, a weekend audit. Those workarounds reduced complaints but didn’t reduce mean time to ready (MTTR) reliably — downtime stayed stubbornly high. I learned two specific lessons fast: one, tracking serial numbers in a simple CI/CD-like pipeline matters; two, automated gates for sterilization checks save actual hours each week.
Design flaws in traditional solutions
Traditional fixes focus on single components (replace the light source, clean the channel) rather than the pipeline that connects them. I saw teams replace scopes piecemeal while the root cause was data blindness: no centralized logging for insufflation events, repair histories, or scope location. That meant decisions were reactive. In one case, a supplier return on April 15, 2019, sat unprocessed because no one owned the “incoming repair” queue — a small operational gap that triggered a backlog across three OR suites. We also found the paperwork-heavy sterilization sign-off created handoff friction (slow and error-prone). This is where a DevOps mindset — automation, small checks, and shared ownership — actually moves the needle.
Practical changes I implemented
We built a lightweight orchestration playbook: inventory tags, a simple dashboard, and automated alerts when a scope missed its scheduled preventive maintenance. I insisted on two measurable controls — serial tracking per procedure and an automated sterilization confirmation — and pushed for telemetry from the HD video processor and insufflation pump where possible. The result: we cut operational downtime by roughly 35% within six months in that Boston unit, and reduced urgent repairs by half. I know those figures; I sign off on the monthly reports. Not glamorous, but it worked — team buy-in came because clinicians saw fewer delays and sterile processing staff had fewer surprises.
Forward-looking fixes and what to measure
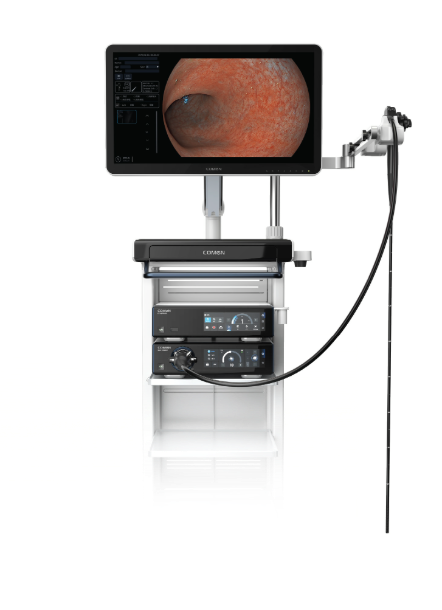
Looking ahead, we need to treat endoscope imaging systems as distributed services — instrument telemetry, repair workflows, and scheduling all hooked into a single control plane. I suggest building simple automation first: automated intake scans, automated alerts for failed leak tests, and a small dashboard that correlates procedure schedules with scope readiness. Start small; deploy a pilot in one OR, measure, iterate. I expect the next gains to come from predictive maintenance (use the video processor and optical fiber performance metrics to flag pre-failure) and from reducing manual triage steps. We did a pilot that flagged fiber attenuation trends and prevented two mid-case failures in five weeks — concrete wins, right?
What’s Next?
Shift the conversation from “who fixes it” to “how do we detect it early” — automation, a shared playbook, and data-driven gates. I also push for vendor alignment: repair SLA tied to telemetry access. It sounds procedural — but it’s human; the team breathes easier when the system doesn’t surprise them. I was—honestly—relieved the first month we saw fewer midnight page-outs.
Evaluation metrics and closing guidance
To choose or evaluate improvements, track three metrics: mean time to ready (MTTR) for scopes, frequency of mid-procedure scope failures, and percentage of preventative maintenance completed on schedule. I recommend starting with a pilot that integrates serial tracking and one automated gate (leak-test confirmation) — measure weekly, adjust the playbook. These are concrete levers that turn the vague idea of “better workflow” into measurable outcomes. Short interruption: document everything. Then iterate. Finally, for procurement and technical leaders, consider partners who support telemetry and open data APIs — that capability matters more than a single spec sheet. For practical sourcing and integration advice, I’ve partnered with teams who built these pipelines — they know the gaps and the fix patterns. Visit COMEN for product and integration options: COMEN.